DAFTAR
ISI
BAB I
PENDAHULUAN
1. Latar
Belakang
Dalam ilmu statistik kita selalu mengenal ukuran mean (rataan), median (nilai tengah) dan modus (nilai terbanyak). Ketiga ukuran ini merupakan ukuran average (rata-rata) dalam
kelompok ukuran pemusatan (central tendency). Ketiga
ukuran statistik ini pun banyak dijumpai penerapannya dalam kehidupan sehari-hari.
Untuk menggambarkan sekelompok data kita sering
menyatakannya dalam mean,
median ataupun modusnya.
Mean atau rataan adalah jumlah seluruh data (sum) dibagi dengan banyaknya
data. Sedangkan median adalah nilai yang tepat berada di tengah-tengah sekelompok
data setelah data kita diurutkan menurut besarnya. Terakhir modus adalah nilai/data
yang paling tinggi frekwensi kemunculannya dalam kelompok data yang kita miliki tersebut.
Meskipun
memiliki definisi yang berbeda-beda, penggunakan ketiga ukuran ini memiliki makna dan maksud yang sama yaitu untuk mewakili ukuran rata-rata (pusat) dari sejumlah data.
Lalu apa perbedaan ketiga ukuran ini? Perbedaannya adalah pada kapan kita
harus menggunakan ketiga ukuran ini. Berikut ini beberapa kondisi yang
menggambarkan penggunaan ketiga ukuran ini:
1.
Skala pengukuran:
Untuk data dengan skala pengukuran interval, pada dasarnya ketiga
ukuran di
atas dapat digunakan. Namun akan lebih baik menggunakan ukuran mean jika jumlah data kita sangat sedikit. Untuk jumlah data yang
sangat
banyak
biasanya data dibuat dulu menjadi
data
berkelompok
kemudian baru dihitung ketiga ukuran tersebut.
Jika skala pengukuran data berupa ordinal, maka ukuran yang bisa
digunakan hanya
median dan
modus, sedangkan
mean tidak
dapat digunakan.Untuk skala pengukuran nominal, ukuran yang bisa digunakan hanyalah modus,
sedangkan dua ukuran
yang lainnya
tidak dapat
digunakan.
2.
Bentuk distribusi frekuensi
Hal yang perlu diperhatikan dalam memilih ukuran yang tepat adalah bentuk distribusi frekuensi. Dalam distribusi normal (sempurna), ketiga ukuran memiliki letak yang sama. Mean menjadi tidak akurat digunakan
pada distribusi yang
menceng.
Dalam kondisi
seperti itu lebih
baik menggunakan median.
2.
Rumusan Masalah
Berdasarkan
latar belakang diatas, maka rumusan masalah yang dibahas dalam makalah ini
terinci sebagai berikut:
1.
Apa
saja kekurangan dan kelebihan rata – rata, median dan modus ?
2.
Apa
saja hubungan antara rata – rata, median, dan modus ?
3.
Tujuan Penulisan
1.
Mengetahui
kekurangan dan kelebihan rata – rata, median dan modus.
2.
Mengetahui
hubungan antara rata – rata, median, dan modus.
BAB
II
PEMBAHASAN
1.
Pengertian Statistik dan Statistika
Statistik adalah kumpulan angka yang sering disusun, diatur, atau disajikan ke dalam bentuk daftar/tabel,
sering pula daftar atau tabel tersebut disertai dengan gambar-gambar yang biasa
disebut diagram atau grafik. Data yang diperoleh itu
dapat berupa
bilangan
yang melukiskan suatu persoalan.
Statistika adalah pengetahuan yang
berhubungan dengan cara-cara pengumpulan
data, pengolahan atau penganalisaannya dan penarikan kesimpulan atau interprestasi terhadap hasil
analisis kumpulan data tersebut. Statistika dikelompokkan dalam dua kelompok yaitu statistika deskriptif dan
statistika inferensia. Statistika deskriptif adalah metode yang berkaitandengan pengumpulan dan penyajian suatu gugus data sehingga memberikan
informasi yang berguna. Statistika deskriptif ini
menggambarkan dan menganalisa data dalam suatu kelompok tanpa membuat/ menarik
kesimpulan tentang populasi atau kelompok yang lebih besar. Sedangkan pengertian
statistika inferensia adalah metode yang
berhubungan dengan analisis sebagian data untuk kemudian sampai pada peramalan atau penarikan kesimpulan tentang seluruh gugus data induknya. Dalam statitistik inferensial berkaitan dengan
kondisi-kondisi dimana data dari sampel dianalisis tersebut ditarik kesimpulan
untuk populasi dari mana sampel tersebut diambil.
2.
Data dalam Statistik
Data adalah ukuran dari
variabel. Data diperoleh dengan mengukur nilai satu atau lebih variabel dalam
sampel (atau populasi). Data dapat diklasifikasikan menurut jenis, menurut
dimensi waktu, dan menurut sumbernya.
Menurut jenisnya, data terdiri
dari :
a.
Data
kuantitatif adalah
data yang diukur dalam suatu skala numerik (angka). Data kuantitatif dapat
dibedakan menjadi:
1)
Data
interval,
yaitu data yang diukur dengan jarak di antara dua titik pada skala yang sudah
diketahui. Sebagai contoh: IPK mahasiswa (interval 0 hingga 4); usia produktif
(interval 15 hingga 55 tahun); suhu udara dalam Celcius (interval 0 hingga 100
derajat).
2)
Data
rasio,
yaitu data yang diukur dengan suatu proporsi. Sebagai contoh: persentase jumlah
pengangguran di Propinsi Sumatera Utara; tingkat inflasi Indonesia pada tahun
2000; persentase penduduk miskin di Sumatera Utara; pertumbuhan ekonomi
Sumatera Utara
b.
Data
kualitatif,
adalah data yang tidak dapat diukur dalam skala numerik. Namun karena dalam
statistik semua data harus dalam bentuk angka, maka data kualitatif umumnya
dikuantifikasi agar dapat diproses. Kuantifikasi dapat dilakukan dengan
mengklasifikasikan data dalam bentuk kategori. Data kualitatif dapat dibedakan
menjadi:
1)
Data
nominal,
yaitu data yang dinyatakan dalam bentuk kategori. Sebagai contoh, industri di
Indonesia oleh Biro Pusat Statistik digolongkan menjadi:
a)
Industri
rumah tangga, dengan jumlah tenaga kerjanya 1-4 orang, yang diberi kategori 1.
b)
Industri
kecil, dengan jumlah tenaga 5-19 orang, yang diberi kategori 2.
c)
Industri
menengah, dengan jumlah tenaga kerja 20-100 orang, yang diberi kategori 3.
d) Industri besar, dengan
jumlah tenaga kerja lebih dari 100 orang, yang diberi kategori 4.
2)
Data
ordinal,
yaitu data yang dinyatakan dalam bentuk kategori, namun posisi data tidak sama
derajatnya karena dinyatakan dalam skala peringkat. Sebagai contoh, dalam skala
likert.
Menurut sumbernya, data terdiri
dari :
a.
Data Primer yaitu data yang
diperoleh secara langsung dengan melakukan sendiri pengumpulan terhadap obyek.
b.
Data Sekunder yaitu data yang
diperoleh dari olahan data primer
c.
Data Tersier yaitu data yang
diperoleh dari olahan data sekunder.
d.
Data Kuarter yaitu data yang
diperoleh dari data tersier yang telah diolah terlebih dahulu.
3.
Pengertian Populasi
Menurut Sugiyono (2001: 55) populasi
adalah wilayah generalisasi yang terdiri atas objek/subjek yang mempunyai
kuantitas dan karakteristik tertentu yang ditetapkan oleh peneliti untuk
dipelajari dan kemudian ditarik Jadi populasi bukan hanya orang, tetapi juga
benda-benda alam yang lain. populasi juga bukan sekedar jumlah yang ada pada
objek/subjek yang dipelajari, tetapi meliputi seluruh karakteristik/sifat yang
dimiliki oleh objek atau subjek itu.
4.
Pengertian Sampel
Menurut Sugiyono, Sampel adalah
sebagian dari jumlah dan karakteristik yang dimiliki oleh populasi tersebut.
5.
Pengertian Variabel
Menurut Sugiarto, Variabel adalah
karakter yang akan diobservasi dari unit amatan yang merupakan suatu atribut
dari sekelompok objek dengan ciri adanya variasi antara satu objek dengan objek
yang lain dalam kelompok tertentu.
6.
Cara Pengumpulan
Data
Secara umum ada tiga cara untuk
mengumpulkan data, yaitu pertama melalui metode observasi, metode wawancara,
dan metode kuesioner.
a.
Metode Observasi
Pengumpulan data dengan observasi
langsung atau dengan pengamatan langsung adalah cara pengambilan data dengan
menggunakan mata tanpa ada pertolongan alat standar lain untuk keperluan
tersebut. Pengamatan baru tergolong sebagai teknik mengumpulkan data, jika
pengamatan tersebut mempunyai kriteria berikut:
1)
Pengamatan digunakan untuk
penelitian dan telah direncanakan secara sistematik.
2)
Pengamatan harus berkaitan dengan
tujuan penelitian yang telah direncanakan.
3)
Pengamatan tersebut dicatat secara
sistematis dan dihubungkan dengan proposisi umum dan bukan dipaparkan sebagai
suatu set yang menarik perhatian saja.
Pengamatan dapat dicek dan dikontrol
atas validitas dan reliabilitasnya.Penggunaan pengamatan langsung sebagai cara
mengumpulkan data mempunyai beberapa keuntungan antara lain :
1)
Dengan cara pengamatan langsung,
terdapat kemungkinan untuk mencatat hal-hal, perilaku, pertumbuhan, dan
sebagainya, sewaktu kejadian tersebut berlaku, atau sewaktu perilaku tersebut
terjadi. Dengan cara pengamatan, data yang langsung mengenai perilaku yang
tipikal dari objek dapat dicatat segera, dantidak menggantungkan data dari
ingatan seseorang;
2)
Pengamatan langsung dapat memperoleh
data dari subjek baik tidak dapat berkomunikasi secara verbal atau yang tak mau
berkomunikasi secara verbal. Adakalanya subjek tidak mau berkomunikasi, secara
verbal dengan enumerator atau peneliti, baik karena takut, karena tidak ada
waktu atau karena enggan. Dengan pengamatan langsung, hal di atas dapat
ditanggulangi. Selain dari keuntungan yang telah diberikan di atas, pengamatan
secara langsung sebagai salah satu metode dalam mengumpulkan data, mempunyai
kelemahan-kelemahan.
b.
Metode Wawancara
Yang dimaksud dengan wawancara
adalah proses memperoleh keterangan untuk tujuan penelitian dengan cara tanya
jawab, sambil bertatap muka antara si penanya atau pewawancara dengan si
penjawab atau responden dengan menggunakan alat yang dinamakan interview guide
(panduan wawancara). Wawancara dapat dilakukan dengan tatap muka maupun melalui
telpon.
1)
Wawancara Tatap Muka
Kelebihan :
·
Bisa membangun hubungan dan
memotivasi responden
·
Bisa mengklarifikasi pertanyaan,
menjernihkan keraguan, menambah pertanyaan baru
·
Bisa membaca isyarat non verbal
·
Bisa memperoleh data yang banyak
Kekurangan :
·
Membutuhkan waktu yang lama
·
Biaya besar jika responden yang akan
diwawancara berada di beberapa daerah terpisah
·
Responden mungkin meragukan
kerahasiaan informasi yang diberikan
·
Pewawancara perlu dilatih
·
Bisa menimbulkan bias pewawancara
·
Responden bias menghentikan
wawancara kapanpun
2)
Wawancara via phone
Kelebihan
·
Biaya lebih sedikit dan lebih cepat
dari warancara tatap muka
·
Bisa menjangkau daerah geografis
yang luas
·
Anomalitas lebih besar dibanding
wawancara pribadi (tatap muka)
Kelemahan
·
Isyarat non verbal tidak bisa dibaca
·
Wawancara harus diusahakan singkat
·
Nomor telpon yang tidak terpakai
bisa dihubungi, dan nomor yang tidak terdaftar pun dihilangkan dari sampel
c.
Metode Kuesioner
Kuesioner adalah daftar pertanyaan
tertulis yang telah disusun sebelumnya.Pertanyaan-pertanyaan yang terdapat
dalam kuesioner, atau daftar pertanyaan tersebut cukup terperinci dan lengkap
dan biasanya sudah menyediakan pilihan jawaban (kuesioner tertutup) atau
memberikan kesempatan responden menjawab secara bebas (kuesioner terbuka).
Penyebaran kuesioner dapat dilakukan
dengan beberapa cara seperti penyerahan kuesioner secara pribadi, melalui
surat, dan melalui email. Masing-masing cara ini memiliki kelebihan dan
kelemahan, seperti kuesioner yang diserahkan secara pribadi dapat membangun
hubungan dan memotivasi respoinden, lebih murah jika pemberiannya dilakukan
langsung dalam satu kelompok, respon cukup tinggi. Namun kelemahannya adalah
organisasi kemungkinan menolak memberikan waktu perusahaan untuk survey dengan
kelompok karyawan yang dikumpulkan untuk tujuan tersebut.
7.
Penyajian Data
Ada dua cara penyajian data yang sering dilakukan, yaitu :
a.
Penyajian
Data dalam Bentuk Tabel
b.
Penyajian
Data dalam Bentuk Diagram
1)
Diagram
Batang / HISTOGRAM
Diagram batang biasanya digunakan untuk menggambarkan data diskrit
(data cacahan).Diagram batang adalah bentuk penyajian data statistik dalam
bentuk batang yang dicatat dalam interval tertentu pada bidang cartesius.Ada
dua jenis diagram batang, yaitu:
a)
diagram batang vertikal, dan
b)
diagram batang horizontal.
Diagram batang atau histogram merupakan salah satu jenis
bentuk diagram yang digunakan untuk penyajian data. Disebut diagram batang
karena terdiri dari beberapa batang yang disusun secara vertikal atau
horisontal. Untuk menggambar diagram batang diperlukan dua sumbu yaitu sumbu
mendatar (horizontal) dan sumbu tegak (vertikal) yang saling berpotongan secara
tegak lurus.
2)
Diagram
Garis
Diagram garis biasanya digunakan untuk menggambarkan keadaan
yang berkesinambungan.Grafik atau diagram garis juga memerlukan sistem sumbu
datar dan sumbu tegak yang saling berpotongan tegak lurus. Pada umumnya, sumbu
datar menunjukkan waktu, sedangkan sumbu tegak menunjukkan data yang berubah
menurut waktu.Seperti halnya diagram batang, diagram garis pun memerlukan
sistem sumbu datar (horizontal) dan sumbu tegak (vertikal) yang saling
berpotongan tegak lurus. Sumbu mendatar biasanya menyatakan jenis data,
misalnya waktu dan berat.Adapun sumbu tegaknya menyatakan frekuensi data.
3)
Diagram Lingkaran
Untuk mengetahui perbandingan suatu
data terhadap keseluruhan, suatu data lebih tepat disajikan dalam bentuk
diagram lingkaran.Diagram lingkaran adalah bentuk penyajian data statistika
dalam bentuk lingkaran yang dibagi menjadi beberapa juring lingkaran.
Diagram lingkaran merupakan salah
satu penyajian data statistik yang berbentuk lingkaran. Biasanya diagram
lingkaran dinyatakan dalam bentuk derajat atau persentase. Langkah-langkah
membuat diagram lingkaran yakni: membuat sebuah lingkaran pada kertas kemudian
membagi lingkaran tersebut menjadi beberapa juring lingkaran
untuk menggambarkan kategori yang datanya telah diubah ke dalam derajat atau
persentase.
4)
Diagram Gambar atau Piktogram
Menurut wikipedia, piktogram adalah suatu ideogram yang menyampaikan suatu
makna melalui penampakan gambar yang menyerupai atau meniru keadaan fisik objek
yang sebenarnya.Berikut di bawah ini merupakan contoh gambar piktogram.

Piktogram ini bisa digunakan untuk menyajikan suatu data
statistik yang sering disebut sebagai diagram gambar. Jadi, diagram gambar atau
piktogram adalah bagan yang menampilkan data dalam bentuk gambar. Menyajikan
data dalam bentuk piktogram merupakan cara yang paling sederhana.
8.
Tabel Distribusi
Beberapa istilah pada tabel
frekuensi
·
INTERVAL
KELAS adalah interval yang diberikan
untuk menetapkan kelas-kelas dalam distribusi. Pada tabel 2.1, interval
kelasnya adalah 60-62, 63-65, 66-68, 69-71 dan 72-74. Interval kelas 66-68
secara matematis merupakan interval tertutup [66, 68], ia memuat semua bilangan
dari 66 sampai dengan 68. Bilangan 60 dan 62 pada interval 60-62 disebut limit
kelas, dimana angka 60 disebut limit kelas bawah dan angka 62 disebut limit
kelas atas.
·
BATAS
KELAS adalah bilangan terkecil dan
terbesar sesungguhnya yang masuk dalam 60 – 62. Bilangan 59.5 dan 62.5 ini
disebut batas kelas atau limit kelas sesungguhnya, kelas interval tertentu.
Misalnya jika dalam pengukuran tinggi badan di atas dilakukan dengan ketelitian
0.5 in maka tinggi badan 59.5 in dan 62.5 in dimasukkan ke dalam kelas dimana
bilangan 59.5 disebut batas kelas bawah dan 62.5 disebut batas kelas atas. Pada
prakteknya batas kelas interval ini ditentukan berdasarkan rata-rata limit
kelas atas suatu interval kelas dan limit kelas bawah interval kelas
berikutnya. Misalnya batas kelas 62.5 diperoleh dari (62+63)/2. Pemahaman yang
sama untuk interval kelas lainnya.
·
LEBAR/PANJANG
INTERVAL KELAS adalah selisih antara batas atas
dan batas bawah batas kelas. Misalnya lebar intervl kelas 60-62 adalah
62.5–59.5 = 3
·
TANDA
KELAS adalah titik tengah interval kelas.
Ia diperoleh dengan cara membagi dua jumlah dari limit bawah dan limit atas
suatu interval kelas. Contoh tanda kelas untuk kelas interval 66-68 adalah
(66+68)/2 = 67.
9.
Prosedur Umum Membuat
Tabel Frekuensi
Langkah-langkah penyusunan tabel distribusi frekuensi adalah
sebagai berikut.
a.
Menentukan jangkauan data (r) = data
max – data min
b.
Menentukan banyak interval (K)
dengan rumus "Sturgess" yaitu: K= 1 + 3,3 log n dengan n adalah
banyak data. Banyak kelas harus merupakan bilangan bulat positif hasil
pembulatan.
c.
Menentukan panjang interval kelas
(I) dengan menggunakan rumus:
I = J/K
d.
Menentukan batas-batas kelas. Data
terkecil harus merupakan batas bawah interval kelas pertama atau data terbesar
adalah batas atas interval kelas terakhir.
e.
Memasukkan data ke dalam kelas-kelas
yang sesuai dan menentukan nilai frekuensi setiap kelas dengan sistem turus.
f.
Menuliskan turus-turus dalambilangan
yang bersesuaian dengan banyak turus.
10.
Frekuensi Relatif
dan Kumulatif
Frekuensi yang dimiliki setiap kelas
pada tabel distribusi frekuensi bersifat mutlak.Adapun frekuensi relatif dari
suatu data adalah dengan membandingkan frekuensi pada interval kelas itu dengan
banyak data dinyatakan dalam persen.
Frekuensi
relatif dirumuskan sebagai berikut.
Frekuensi relatif kelas
ke-k = frekuensi kelas ke-k / banyak data
Frekuensi kumulatif kelas ke-k adalah jumlah frekuensi pada
kelas yang dimaksud dengan frekuensi kelas-kelas sebelumnya.Ada dua macam
frekuensi kumulatif, yaitu:
a.
frekuensi kumulatif "kurang dari"
("kurang dari" diambil terhadap tepi atas kelas);
b.
frekuensi kumulatif "lebih
dari" ("lebih dari" diambil terhadap tepi bawah kelas).
Tepi atas = batas atas + ½ satuan pengukuran
Tepi bawah = batas bawah - ½ satuan pengukuran
11.
Histogram dan
Poligon Frekuensi
Histogram merupakan diagram
frekuensi bertangga yang bentuknya seperti diagram batang. Batang yang
berdekatan harus berimpit.Untuk pembuatan histogram, pada setiap interval kelas
diperlukan tepi-tepi kelas.Tepi-tepi kelas ini digunakan unntuk menentukan
titik tengah kelas yang dapat ditulis sebagai berikut.
Titik tengah kelas
= ½ (tepi atas kelas + tepi bawah kelas)
Poligon frekuensi dapat dibuat dengan menghubungkan
titik-titik tengah setiap puncak persegipanjang dari histogram secara berurutan.Agar
poligon "tertutup" maka sebelum kelas paling bawah dan setelah kelas
paling atas, masing-masing ditambah satu kelas.
Contoh Soal :
Tabel distribusi frekuensi hasil ujian matematika Kelas XI
SMA Cendekia di Kalimantan Barat diberikan pada Tabel 6.Buatlah histogram dan
poligon frekuensinya.
Tablel 6.Tabel distribusi frekuensi hasil ujian matematika SMA
Cendekia.
|
Kelas Interval
|
Frekuensi
|
|
21–30
|
2
|
|
31–40
|
3
|
|
41–50
|
11
|
|
51–60
|
20
|
|
61–70
|
33
|
|
71–80
|
24
|
|
81–90
|
7
|
|
100
|
Jawaban :
 |
|
Gambar
4. Histogram hasil ujian matematika SMA Cendekia.
|
12.
Ogive (Ogif)
Grafik yang menunjukkan frekuensi
kumulatif kurang dari atau frekuensi kumulatif lebih dari dinamakan poligon
kumulatif.
Untuk populasi yang besar, poligon
mempunyai banyak ruas garis patah yang menyerupai kurva sehingga poligon
frekuensi kumulatif dibuat mulus, yang hasilnya disebut ogif.
Ada dua macam ogif, yaitu sebagai berikut.
a. Ogif dari frekuensi kumulatif kurang dari disebut ogif
positif.
b. Ogif dari frekuensi kumulatif lebih dari disebut ogif
negatif.
Contoh Soal :
Tabel 7.dan 8. berturut-turut adalah tabel distribusi
frekuensi kumulatif "kurang dari" dan "lebih dari" tentang
nilai ulangan Biologi Kelas XI SMA 3.
Tabel 7.Tabel distribusi frekuensi kumulatif "kurang
dari" tentang nilai ulangan Biologi Kelas XI SMA 3.
|
Nilai
|
Frekuensi
|
|
< 20,5
|
0
|
|
< 30,5
|
2
|
|
< 40,5
|
5
|
|
< 50,5
|
16
|
|
< 60,5
|
36
|
|
< 70,5
|
69
|
|
< 80,5
|
93
|
|
< 90,5
|
100
|
Tabel 8.Tabel distribusi frekuensi
kumulatif "lebih dari" tentang nilai ulangan Biologi Kelas
XI SMA 3.
|
Nilai
|
Frekuensi
|
|
> 20,5
|
100
|
|
> 30,5
|
98
|
|
> 40,5
|
95
|
|
> 50,5
|
84
|
|
> 60,5
|
64
|
|
> 70,5
|
31
|
|
> 80,5
|
7
|
|
> 90,5
|
0
|
Pembahasan :
Ogif positif dan ogif negatif dari
tabel tersebut
 |
|
Gambar
5. Kurva ogif positif dan negatif
|
13. Ukuran Lokasi dan Ukuran Tendensi Sentral
Salah satu ukuran numerik yang
penting adalah ukuran lokasi, yaitu suatu ukuran sepanjang garis horizontal
yang letaknya ditengah distribusi data.Ukuran lokasi sekumpulan data adalah
nilai yang representatif bagi keseluruhan nilai data atau dapat menggambarkan
distribusi data itu, khususnya dalam hal letaknya (lokasinya).Nilai tersebut
dihitung dari keseluruhan data bersangkutan sehingga cenderung terletak
diurutan tengah atau pusat setelah data diurutkan menurut besarnya. Oleh karena
itu, nilai tunggal tersebut sering dinamakan ukuran tendensi sentral (measures
of central tendency) atau ukuran nilai sentral (measures of central value).
Beberapa ukuran lokasi yang akan dibicarakan adalah mean, mean terbobot,
median, kuartil dan modus.
a.
Ukuran Tendensi Sentral (Central
Tendency Measurement)
1)
Rata-rata (Mean)
Data tunggal
Diketahui data : 3, 4,
5, 2, 6, 7, 4, 6, 3, 5. hitung nilai rata – ratanya!
Jawab :
Mean = ∑Xi
N
=
3 + 4 + 5 + 2 + 6 + 7 + 4 + 6 + 3+ 5
9
=
45
9
= 5
Data berkelompok
|
∑fi
Contoh menghitung rata
- rata data kelompok :
|
Nilai
|
f
|
m
|
|
1 -5
6 -10
11 – 15
16 – 20
21 – 25
26 – 30
31 – 35
36 – 40
41 – 45
46 - 50
|
3
7
4
3
7
9
6
7
8
6
|
3
8
13
18
23
28
33
38
43
48
|
|
60
|
Jawab :
Mean = ∑(fi.mi)
∑fi
= {(3.3)+(7.8)+(4.13)+(3.18)+(7.23)+(9.28)+(6.33)+
(7.38)+(8.43)+(6.48)} .
60
={9+56+52+54+161+252+198+266+344+288}
60
= 1680
60
= 28
2)
Nilai Tengah (Median)
Data Tunggal
Med = (N+1)/2
Ket :
N = Jumlah data
Contoh :
Diketahui data :2, 3, 3, 4, 4, 5, 5, 6, 6, 7.
Med = 10+1 / 2 = 5,5
Data ke-5,5 berada diantara angka 4 dan 5 maka ….
Med = 4 + 5
2
= 4,5
|
Med
= Lm + ( N/2 - ∑f ) . C
fm
Contoh:
|
Nilai
|
fm
|
F
|
|
1
-5
6 -10
11 – 15
16 – 20
21 – 25
26 – 30
31 – 35
36 – 40
41 – 45
46 - 50
|
3
7
4
3
7
9
6
7
8
6
|
3
10
14
17
24
33
39
46
54
60
|
|
60
|
Kelas median
Jawab :
kelas median =1/2.n
= ½.60
= 30
Berada pada kelas 26-30
Lm = 26 - 0,5 = 25,5
N = 60
∑f = 24
C = 5
fm = 9
Med = Lm + ( N/2 - ∑f ) . C
fm
=
25,5 + (60/2 – 24) . 5
9
=25,5 + (30 – 24) . 5
9
= 25,5 + 0,67 . 5
=25,5 +3,35=28,85
3)
Modus
Modus data tunggal :
Berapakah modus dari data berikut : 1,2,2,4 ,4 ,4,5 ,6 ,7,8
,9 .
Jawab
Modus = 4 ,karena
angka 4 muncul paling banyak yaitu 3 kali.
Modus data kelompok
Mod = Lmo +
d1 . c
d1 + d2
Ket :
Lmo = Tepi bawah kelas modus
d1 = selisih
antara frekuensi kelas modus dengan
frekuensi kelas sebelum modus
d2 = selisih
antara frekuensi kelas modus dengan
frekuensi kelas sesudah modus
c = interval
kelas modus
Contoh:
|
Nilai
|
fm
|
F
|
|
1 -5
6 -10
11 – 15
16 – 20
21 – 25
26 – 30
31 – 35
36 – 40
41 – 45
46 - 50
|
3
7
4
3
7
9
6
7
8
6
|
3
10
14
17
24
33
39
46
54
60
|
|
60
|
Kelas modus
Jawab :
Kelas modus 26 – 30
(karena memiliki frekuensi terbanyak = 9)
Lmo = 26 – 0,5 = 25,5
d1 = 9 – 7 = 2
d2 = 9 – 6 = 3
c = 5
Mod = Lmo + d1
.c
d1 + d2
=25,5 + 2.5
2 + 3
= 25,5 + 0,4 . 5
= 25,5 + 2
= 27,5
14. Kelebihan dan Kekurangan Rata-rata, Median
dan Modus
a.
Rata-rata
Kelebihan
1)
Rata-rata lebih populer dan lebih
mudah digunakan.
2)
Dalam satu set data, rata-rata
selalu ada dan hanya ada satu rata-rata.
3)
Dalam penghitungannya selalu
mempertimbangkan semua nilai data.
4)
Tidak peka terhadap penambahan
jumlah data.
5)
Variasinya paling stabil.
6)
Cocok digunakan untuk data yang
homogen.
Kelemahan
1)
Sangat peka terhadap data ekstrim.
Jika data ekstrimnya banyak, rata-rata menjadi kurang mewakili (representatif).
2)
Tidak dapat digunakan untuk data
kualitatif.
3)
Tidak cocok untuk data heterogen.
b.
Median
Kelebihan
1)
Tidak dipengaruhi oleh data ekstrim.
2)
Dapat digunakan untuk data
kualitatif maupun kuantitatif.
3)
Cocok untuk data heterogen.
Kelemahan
1)
Tidak mempertimbangkan semua nilai
data.
2)
Kurang menggambarkan rata-rata
populasi.
3)
Peka terhadap penambahan jumlah
data.
c.
Modus
Kelebihan
1)
Tidak dipengaruhi oleh data ekstrim.
2)
Cocok digunakan untuk data
kuantitatif maupun kualitatif.
Kelemahan
1)
Modus tidak selalu ada dalam satu
set data.
2)
Kadang dalam satu set data terdapat
dua atau lebih modus. Jika hal itu terjadi modus menjadi sulit digunakan.
3)
Kurang mempertimbangkan semua nilai.
4)
Peka terhadap penambahan jumlah
data.
15. Hubungan Antara Rata-rata Hitung (Mean),
Median dan Modus
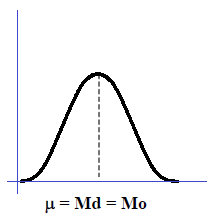
·
Jika rata-rata, median dan modus
memiliki nilai yang sama, maka nilai rata-rata, median dan modus akan terletak
pada satu titik dalam kurva distribusi frekuensi. Kurva distribusi frekuensi
tersebut akan terbentuk simetris.
·
Jika rata-rata lebih besar dari
median, dan median lebih besar dari modus, maka pada kurva distribusi
frekuensi, nilai rata-rata akan terletak di sebelah kanan, sedangkan median
terletak di tengahnya dan modus di sebelah kiri. Kurva distribusi frekuensi akan
terbentuk menceng ke kiri.

·
Jika rata-rata lebih kecil dari
median, dan median lebih kecil dari modus, maka pada kurva distribusi
frekuensi, nilai rata-rata akan terletak di sebelah kiri, sedangkan median
terletak di tengahnya dan modus di sebelah kanan. Kurva distribusi frekuensi
akan terbentuk menceng ke kanan.

·
Jika kurva distribusi frekuensi
tidak simetris (menceng ke kiri atau ke kanan), maka biasanya akan berlaku
hubungan antara rata-rata median dan modus sebagai berikut. Rata-rata –
Modus = 3 (Rata-rata – Median)
16.
Kuartil
Istilah kuartil dalam kehidupan kita
sehari-hari lebih dikenal dengan istilah kuartal.
Dalam dunia statistik, yang dimaksud
dengan kuartil ialah titik atau skor atau nilai yang membagi seluruh distribusi
frekuensi ke dalam empat bagian yang sama besar, yaitu masing masing sebesar ¼
N. jadi disini akan kita jumpai tiga buah kuartil, yaitu kuartil pertama (Q1),
kuartil kedua (Q2), dan kuartil ketiga (Q3). Ketiga kuartil inilah yang membagi
seluruh distribusi frekuensi dari data yang kita selidiki menjadi empat bagian
yang sama besar, masing-masing sebesar ¼ N, seperti terlihat dibawah ini
Jalan pikiran serta metode yang
digunakan adalah sebagaimana yang telah kita lakukan pada saat kita menghitung
median. Hanya saja, kalau median membagi seluruh distribusi data menjadi dua
bagian yang sama besar, maka kuartil membagiseluruh distribusi data menjadi
empat bagian yang sama besar. Jika kita perhatikan pada kurva tadi, maka dapat
ditarik pengertian bahwa Q2 adalah sama dengan Median(2/4 N=1/2 N).
Untuk mencari Q1,Q2 dan Q3 digunakan rumus sebagai berikut:
untuk data tunggal
Qn = 1
+ ( n/4N-fkb)
fi
untuk data kelompok
Qn = 1 + (n/4N-fkb)x i
Fi
Qn =
kuartil yang ke-n. karena titik kuartil ada tiga buah, maka n dapat
diisi
dengan bilangan: 1,2, dan 3.
1
= lower limit ( batas bawah nyata
dari skor atau interval yang
mengandung
Qn).
N =
Number of cases.
Fkb =
frekuensi kumulatif yang terletak dibawah skor atau interval yang
mengandung
Qn.
Fi =
frekuensi aslinya (yaitu frekuensi dari skor atau interval yang
mengandung
Qn).
I =
interval class atau kelas interval.
Catatan: - istilah skor berlaku untuk data tunggal.
- istilah interval
berlaku untuk data kelompok.
1)
Contoh perhitungan kuartil untuk
data tunggal
Misalkan dari 60 orang siswa MAN
Jurusan IPA diperoleh nilai hasil EBTA bidang studi Fisika sebagaimana tertera
pada table distribusi frekuensi berikut ini. Jika kita ingin mencari Q1, Q2,
dan Q3 (artinya data tersebut akan kita bagi dalam empat bagian yang sama
besar), maka proses perhitungannya adalah sebagai berikut:
Table 3.11. Distribusi frekuensi
nilai hasil Ebta dalam bidang studi fisika dari 60 orang siswa MAN jurusan ipa,
dan perhitungan Q1, Q2, dan Q3.
|
Nilai
(x)
|
F
|
Fkb
|
|
46
45
44
43
42
41
40
39
38
37
36
35
|
2
2
3
5
F1
(8)
10
F1
(12)
F1
(6)
5
4
2
1
|
60=
N
58
56
53
48
40
30
18
12
7
3
1
|
·
Titik Q1= 1/4N = ¼ X 60 = 15 (
terletak pada skor 39).
Dengan demikian dapat kita ketahui: 1= 38,50; fi = 6; fkb =
12
Q1 = 1 + ( n/4N-fkb) = 38,50 +(15-12)
Fi
6
= 38,50 +0,50
= 39
·
Titik Q2= 2/4N = 2/4 X 60 = 30 (
terletak pada skor 40). Dengan demikian dapat kita ketahui: 1= 39,50; fi = 12;
fkb = 18
Q2 = 1 + ( n/4N-fkb) = 39,50 +(30-18)
Fi
12
= 39,50 +1,0
= 40,50
·
Titik Q3= 3/4N = 3/4 X 60 = 45 (
terletak pada skor 42). Dengan demikian dapat kita ketahui: 1= 41,50; fi = 8;
fkb = 40
Q3 = 1 + ( n/4N-fkb) = 41,50 +(45-40)
Fi
8
= 41,50+ 0,625
= 42,125
2)
Contoh perhitungan kuartil untuk
data kelompok
Misalkan dari 80 orang siswa MAN
jurusan IPS diperoleh skor hasil EBTA dalam bidan studi tata buku sebagaimana
disajikan pada tabel distribusi frekuensi beikut ini ( lihat kolom 1 dan 2).
Jika kita ingin mencari Q1, Q2, dan Q3, maka proses perhitungannya adalah
sebagai berikut:
·
Titik Q1= 1/4N = ¼ X 80 = 20 (
terletak pada interval 35-39). Dengan demikian dapat kita ketahui: 1= 34,50; fi
= 7; fkb = 13, i= 5.
Q1 = 1 + ( n/4N-fkb) Xi = 34,50 +(20-13) X5
Fi
7
= 34,50 +5
= 39,50
·
Titik Q2= 2/4N = 2/4 X 80 = 40 (
terletak pada interval 45-49). Dengan demikian dapat kita ketahui: 1= 44,50; fi
= 17; fkb = 35, i= 5.
Q1 = 1 + ( n/4N-fkb) Xi = 44,50 +(40-35) X5
Fi
17
= 44,50 +1.47= 45,97
·
Titik Q3= 3/4N = 3/4 X 80 = 60 (
terletak pada interval 55-59). Dengan demikian dapat kita ketahui: 1= 54,50; fi
= 7; fkb = 59, i= 5.
Q1 = 1 + ( n/4N-fkb) Xi = 54,50 +(55-59) X5
Fi
7
= 54,50 + 0,71
= 55,21
Tabel 3.12.distribusi frekuensi skor-skor hasil EBTA bidang
studi tata buku dari 80 orang siswa man jurusan ips, berikut perhitungan Q1,Q2,
dan Q3.
|
Nilai
(x)
|
F
|
Fkb
|
|
70-74
65-69
60-64
55-59
50-54
45-49
40-44
35-39
30-34
25-29
20-24
|
3
5
6
7
7
17
15
7
6
5
2
|
80
77
72
66
59
52
35
20
13
7
2
|
|
Total
|
80=
N
|
-
|
Diantara kegunaan kuartil adalah untuk mengetahui simetris
(normal) atau simetrisnya suatu kurva. Dalam hal ini patokan yang kita gunakan
adalah sebagai berikut:
a)
Jika Q3-Q2 = Q2- Q1 maka kurvanya
adalah kurva normal.
b)
Jika Q3-Q2 > Q2- Q1 maka kurvanya
adalah kurva miring/ berat ke kiri(juling positif).
c)
Jika Q3-Q2 < Q2- Q1 maka kurvanya
adalah kurva miring/ berat ke kanan(juling negatif).
17.
Desil
Desil ialah titik atau skor atau
nilai yang membagi seluruh distribusi frekuensi dari data yang kita selidiki ke
dalam 10 bagian yang sama besar, yang masing-masing sebesar 1/10 N. jadi disini
kita jumpai sebanyak 9 buah titik desil, dimana kesembilan buah titik desil itu
membagi seluruh distribusi frekuensi ke dalam 10 bagian yang sama besar. Lambang
dari desil adalah D. jadi 9 buah titik desil dimaksud diatas adalah
titik-titik: D1, D2, D3, D4, D5, D6, D7, D8, dan D9.
Perhatikanlah kurva dibawah ini:
Untuk mencari desil, digunakan rumus sebagai berikut:
Dn= 1 +(n/10N – fkb)
Fi
Untuk data kelompok:
Dn= 1+ (n/10N- fkb) xi
Fi
Dn =
desil yang ke-n (disini n dapat diisi dengan bilangan:1, 2, 3, 4, 5, 6, 7,
8,
atau 9.
1
= lower limit( batas bawah nyata
dari skor atau interval yang
mengandung desil ke-n).
N =
number of cases.
Fkb =
frekuensi kumulatif yang terletak dibawah skor atau interval yang
mengandung
desil ke-n.
Fi =
frekuensi dari skor atau interval yang mengandung desil ke-n, atau
frekuensi
aslinya.
I =interval
class atau kelas interval.
1)
Contoh perhitungan desil untuk data
tunggal
Misalkan kita ingin mencari desil ke-1, ke-5, dan ke-9 atau
D1, D5, dan D9 dari data yang tertera pada table yang telah dihitung Q1, Q2,
dan Q3.
·
Mencari D1:
Titik D1= 1/10N= 1/10X60= 6 (terletak pada skor 37). Dengan
demikian dapat kita ketahui: 1= 5,50; fi= 4, dan fkb= 3.
D1= 1 + (1/10N-fkb) ---D1=36,50 (6-3)
Fi
4
= 36,25
·
Mencari D5:
Titik D5= 5/10N= 5/10X60= 30 (terletak pada skor 40). Dengan
demikian dapat kita ketahui: 1= 39,50; fi= 12, dan fkb= 18.
D1= 1 + (5/10N-fkb) ---D1=39,50 (30-18)
Fi
12
= 40,50
·
Mencari D9:
Titik D9= 9/10N= 9/10X60= 54 (terletak pada skor 44). Dengan
demikian dapat kita ketahui: 1= 43,50; fi= 3, dan fkb= 53.
D1= 1 + (9/10N-fkb) ---D1= 43,50 (54-53)
Fi 3
= 43,17
Tabel 3.13. Perhitungan desil ke-1,
desil ke-5 dan desil ke-9 dari data yang tertera pada table (diatas)
kuartil.
|
Nilai
(x)
|
F
|
Fkb
|
|
46
45
44
43
42
41
40
39
38
37
36
35
|
2
2
3
5
8
10
12
6
5
4
2
1
|
60=
N
58
56
53
48
40
30
18
12
7
3
1
|
2)
Contoh perhitungan desil untuk data
kelompok
Misalkan kita ingin mencari D3 dan D7 dari data yang
tercantum pada table 3.12, proses perhitungannya adalah sebagai berikut:
Table 3.14. Perhitungan desil ke-3 dan desil ke-7 dari data
yang tertera pada table 3.12.
|
Nilai
(x)
|
F
|
Fkb
|
|
70-74
65-69
60-64
55-59
50-54
45-49
40-44
35-39
30-34
25-29
20-24
|
3
5
6
7
7
17
15
7
6
5
2
|
80
77
72
66
59
52
35
20
13
7
2
|
|
Total
|
80=
N
|
-
|
·
Mencari D3:
Titik D3= 3/10N= 3/10X80= 24 (terletak pada interval 40-44).
Dengan demikian dapat kita ketahui: 1= 39,50; fi= 15, dan fkb= 20.
D3= 1 + (3/10N-fkb) xi=39,50 (24-20) x 5
Fi
15
= 39,50+ 20= 39,50 + 1,33= 40,83
15
·
Mencari D7:
Titik D7= 7/10N= 7/10X80= 56 (terletak pada interval 50-54).
Dengan demikian dapat kita ketahui: 1= 49,50; fi= 7, dan fkb= 52.
D7= 1 + (7/10N-fkb) xi=49,50 (50-54) x 5
Fi
7
= 49,50+ 20= 49,50 + 2,86= 40,83
7
Kegunaan desil ialah untuk
menggolongkan-golongkan suatu distribusi data ke dalam sepuluh bagian yang sama
besar, kemudian menempatkan subjek-subjek penelitian ke dalam sepuluh golongan
tersebut.
18.
Persentil
Persentil yang biasa dilambangkan P,
adalah titik atau nilai yang membagi suatu distribusi data menjadi seratus
bagian yang sama besar. Karena itu persentil sering disebut ukuran
perseratusan.
Titik yang membagi distribusi data
ke dalam seratus bagian yang sama besar itu ialah titik-titik: P1, P2, P3, P4,
P5, P6, … dan seterusnya, sampai dengan P99. jadi disini kita dapati sebanyak
99 titik persentil yang membagi seluruh distribusi data ke dalam seratus bagian
yang sama besar, masing-masing sebesar 1/ 100N atau 1%, seperti terlihat pada
kurva dibawah ini:
Untuk mencari persentil digunakan rumus sebagai berikut:
Untuk data tunggal:
Pn= 1 +(n/10N – fkb)
Fi
Untuk data kelompok:
Pn= 1+ (n/10N- fkb) xi
Fi
Pn =
persentil yang ke-n (disini n dapat diisi dengan bilangan-bilangan:1,
2,
3, 4, 5, dan seterusnya sampai dengan 99.
1
= lower limit( batas bawah nyata dari
skor atau interval yang
mengandung
persentil ke-n).
N =
number of cases.
Fkb =
frekuensi kumulatif yang terletak dibawah skor atau interval yang
mengandung
persentil ke-n.
Fi =
frekuensi dari skor atau interval yang mengandung persentil ke-n,
atau
frekuensi aslinya.
I =
interval class atau kelas interval.
Tabel. 3.15. Perhitungan persentil ke-5, persentil ke-20 dan
persentil ke-75 dari data yang tertera pada tabel 3.13.
|
Nilai
(x)
|
F
|
Fkb
|
|
70-74
65-69
60-64
55-59
50-54
45-49
40-44
35-39
30-34
25-29
20-24
|
3
5
6
7
7
17
15
7
6
5
2
|
80
77
72
66
59
52
35
20
13
7
2
|
|
Total
|
80=
N
|
-
|
1)
Contoh perhitungan desil untuk data
tunggal
Misalkan kita ingin mencari persentil ke-5 (P5), persentil
ke-20 (P20), dan ke-75 (P75),dari data yang disajikan pada tabel 3.13 yang telah
dihitung desilnya itu. Cara menghitungnya adalah sebagai berikut:
·
Mencari persentil ke-5 (P5):
Titik P5= 5/10N= 5/10X60= 3 (terletak pada skor 36). Dengan
demikian dapat kita ketahui: 1= 35,50; fi= 2, dan fkb= 1.
P5= 1 + (5/10N-fkb) =36,50 +(3-1)
Fi
2
= 36,50
·
Mencari persentil ke-75 (P75):
Titik P75= 75/10N= 75/10X60= 45 (terletak pada skor 42).
Dengan demikian dapat kita ketahui: 1= 41,50; fi= 8, dan fkb= 40
P75= 1 + (75/10N-fkb) =41,50 +(45-40)
Fi
8
= 42,125
2)
Cara mencari persentil untuk data
kelompok
Misalkan kembali ingin kita cari P35 dan P95 dari data yang
disajikan pada tabel 3.14.
·
Mencari persentil ke-35 (P35):
Titik P35= 35/100N= 35/100X80= 28 (terletak pada interval
40-44). Dengan demikian dapat kita ketahui: 1= 39,50; fi= 15, dan fkb= 20, i=5
P35= 1 + (35/100N-fkb) Xi =39,50 +(45-40) X 5
Fi
8
= 39,50+2,67
= 42,17
·
Mencari persentil ke-95 (P95):
Titik P95= 95/100N= 95/100X80= 76 (terletak pada interval
65-69). Dengan demikian dapat kita ketahui: 1= 64,50; fi= 5, dan fkb= 72, i=5
P95= 1 + (95/100N-fkb) Xi =64,50 +(65-69) X 5
Fi
5
= 64,50+4
= 68,50
Tabel 3.16.Perhitungan persentil
ke-35 dan persentil ke-95 dari data yang tertera pada tabel 3.14.
|
Nilai
(x)
|
F
|
Fkb
|
|
70-74
65-69
60-64
55-59
50-54
45-49
40-44
35-39
30-34
25-29
20-24
|
3
5
6
7
7
17
15
7
6
5
2
|
80
77
72
66
59
52
35
20
13
7
2
|
|
Total
|
80=
N
|
-
|
Kegunaan persentil dalam dunia pendidikan adalah:
a.
Untuk mengubah rawa score (raw data)
menjadi standard score (nilai standar).
b.
Persentil dapat digunakan untuk
menentukan kedudukan seorang anak didik, yaitu: pada persentil keberapakah anak
didik itu memperoleh kedudukan ditengah-tengah kelompoknya.
c.
Persentil juga dapat digunakan
sebagai alat untuk menetapkan nilai batas lulus pada tes atau seleksi.
BAB
III
PENUTUP
Statistik adalah
kumpulan angka yang sering disusun, diatur, atau disajikan ke dalam bentuk daftar/tabel,
sering pula daftar atau tabel tersebut disertai dengan gambar-gambar yang biasa
disebut diagram atau grafik. Data yang diperoleh itu
dapat berupa
bilangan yang melukiskan suatu
persoalan.
Statistika
adalah pengetahuan
yang berhubungan dengan cara-cara pengumpulan
data, pengolahan atau penganalisaannya dan penarikan kesimpulan atau interprestasi terhadap hasil
analisis kumpulan data tersebut. Statistika
dikelompokkan dalam dua kelompok yaitu statistika deskriptif dan
statistika inferensia.
Data adalah ukuran dari variabel. Data
diperoleh dengan mengukur nilai satu atau lebih variabel dalam sampel (atau
populasi). Data dapat diklasifikasikan menurut jenis, menurut dimensi waktu,
dan menurut sumbernya.
Ada dua cara penyajian data yang
sering dilakukan, yaitu :
c.
Penyajian
Data dalam Bentuk Tabel
d.
Penyajian
Data dalam Bentuk Diagram
DAFTAR PUSTAKA
Anto Dajan.
1986. Pengantar Metode Statistik. Jilid II. PT. Pustaka LP3ES Indonesia.
Jakarta.
Aunuddin. 2005.
Statistika: Rancangan dan Analisis Data. IPB Press. Bogor.
Djarwanto PS dan
Pangestu Subagyo. 1994. Statistik Induktif. BPFE Jogyakarta.Jogyakarta.
J. Supranto. 2001.
Statistik: Teori dan Aplikasi. Jilid 2. Edisi Keenam. Erlangga. Jakarta.
Murray R.
Spiegel dan I Nyoman Susila. 1984. Statistik. Erlangga. Jakarta.
Ronald E. Walpole dan Raymond H. Myers.1995. Ilmu Peluang dan Statistika untuk Insinyur dan Ilmuan.Terjemahan oleh RK.Sembiring.ITB Bandung. Bandung.
Ronald E. Walpole dan Raymond H. Myers.1995. Ilmu Peluang dan Statistika untuk Insinyur dan Ilmuan.Terjemahan oleh RK.Sembiring.ITB Bandung. Bandung.
Sutrisno Hadi.
2004. Statistik. Jilid 1. Andi Yogyakarta. Yogyakarta.
Suharyadi,& Purwanto. (2009).
In Statistika untuk Ekonomi dan
Keuangan Modern. Jakarta: Salemba Empat.
Sudjana. (1991). In Statistika. Bandung: Tarsito.
Tidak ada komentar:
Posting Komentar